
Yes, I’m increasingly excited (with an estimated excitement half-life of eight days) about reading lots of academic papers. I always enjoyed hanging out at paper-oriented conferences like SIGCHI, when I was a teenager I would read Nature in the public library and imagined what it would be like to understand a damn thing in it. I remember someone asking Kevin Kelly (pbuh) what he was reading and he said “oh I only read scientific papers these days” which is such a burn. Clearly it is my destiny to read random academic papers and stitch an unassailable theory of life from them. Or at least spend a week lowering my respect for the entire academia.
{kind=link}
Today, I read (which is to say skimmed), Cowgill, Bo, and Eric Zitzewitz. “Corporate Prediction Markets: Evidence from Google, Ford, and Firm X.” The Review of Economic Studies (2015): rdv014, and Rachel Cummings, David M. Pennock, Jennifer Wortman Vaughan. “The Possibilities and Limitations of Private Prediction Markets”, arXiv:1602.07362 [cs.GT] (2016). Look at me, I’m citing.
The main thing I learned is that Google’s internal prediction market worked by letting people turn their fake money won on the market into lottery tickets for a monthly prize (with another prize for most prolific speculator). Clever trick to incentivize people but not turn it into an underground NASDAQ or somesuch.
Meanwhile, I recalled last night the Enron Email Dataset, a publicly available pile of 500,000 emails from 1999-2004. Will it corroborate my evidence that subject lines get longer every year?
Ta-da:
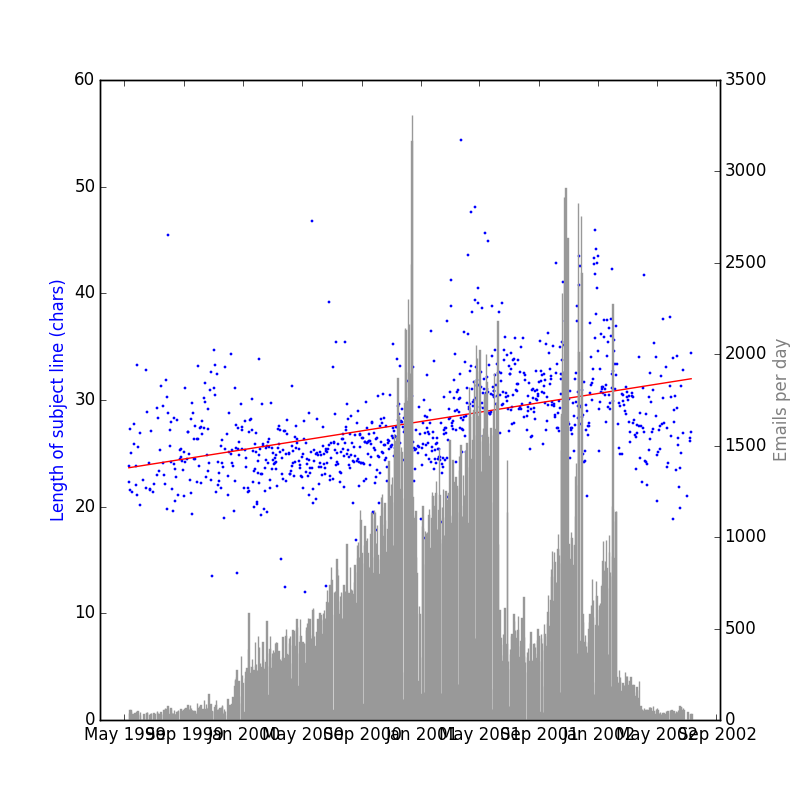
This is a steeper trend over the time period than my own corpus — 2.63 extra characters a year! I’m fretting a bit that it’s some artifact of a rookie statistical mistake I’m making, or the fact that there’s simply being more email over time. Someone who knows more than me on these matters, drop me a line — preferably a very long and descriptive one.
I’ve updated the code to include a function that can parse the Enron Depravities. You can get the latest Enron dataset here (423MB).
March 4th, 2016 at 9:18 am
Danny – first link is broken.
Nice to see you blogging again.