As Was The Style At The Time: How We Became Cruel»
Blah, blah, LLMs: whatever you think of them, you have to admit they are very productive at emitting discourse. Both technically, and by way of their effect on human beings. We seem to be in a cross-substrate language-using competition right now, with carbon-based editorial-writers seeking to produce hot takes as fast as the language models can spit out their own sketchily-grounded expressions. Who will win? Those who buy ink by the gallon or those who generate tokens per kilowatt?
A million years ago, when OpenAI first tentatively opened restricted access to their first large model, I begged and blagged an account on the grounds that someone at EFF should understand the impact of GPT-3 on the Internet and civil liberties. At that point, there was no ChatGPT, and the models really would just autocomplete. The easiest party trick was to get it to replicate literary styles: John Milton writing poems on the nature of the iPhone, Socrates talking to you about Haskell, or, in this 2021 post I made to Facebook depicting free software rhetoric in the style of lurid 19th century gothic novels:
It is GNU/Linux, not Linux, that you should speak of, and free software, not open source, besides! For do you not know that LISP is the programming language of choice for the hacker? And that the hacker who wrote the kernel of your operating system was a LISP programmer? Oh, and do you not know that Richard M. Stallman, founder of the GNU Project, is the hacker who wrote that kernel?
Why, if you were a hacker, you would know this! But you are not a hacker, are you? No, you are merely a parasite, living off the work of the hacker, like the beggar who begs for alms while leaning upon the staff which the peasant has cut from the forest!
(Note the comments on that post: because this was before the general release, this was the first time many people had seen GPT3 at work. There’s quite a bit of early wonderment, concern, and outright skepticism that I’m just bullshitting and pretending to be the AI.)
Literary styles are so fascinating to me, because, while you have some control over how you deploy them in your work — your ability to inflect writing with minor alterations in style is a skill in itself — styles themselves are mostly communally situated. Any writer, consciously or not, plucks and adopts a style from a universal trove. Even if you are a stylistic innovator, how your novel literary form appears to a reader is mostly from its relation to other, or default, forms: Joyce’s Ulysses‘ forms work because of how they stand in relation to what they mimic or how they transgress existing expectations. We adapt previous artforms to our own predicament.
And some styles replicate like some accents replicate. My own accent is presently a geological strata, Californian overturning on top of BBC sandstone. Buried below all that is the London clay of my original Essex accent: soft southerner, cockney with the edges rurally smoothed away. In the decade I was losing it, that accent, Estuary English, conquered millions, before finally meeting its match in Multicultural London English.
I don’t believe in the single genius too much, because to be a single genius would be to be incomprehensible to anyone else. Van Gogh or not, you need to keep a few fingernails clutching onto the rest of the species, else you’re not talking to anyone. Expanding styles is a participatory act.
I know this, because I participated in the creation of a particular style, which I somewhat regret. NTK played its small part in creating Internet snark journalism. It was, I emphasise, a minor contribution; we just pushed the ball along a bit after it had been kicked off by suck.com, and a hoard of Usenet trolls, and Spy Magazine, and Private Eye, and all its lineage. We studied under Armando and Stew, but the only jobs we could get were at the Guardian, so we mixed-and-matched humor with reportage.
At some point, though, I found it corrosive to myself. I spent my days trying to both be entertainingly cruel, factually accurate, and also not hating myself for the sins I committed in both camps. In the end, I spiralled off into sincerity, packed it all in, and joined the circus — or, as I came to know it, the Electronic Frontier Foundation. There, a British person in their first Californian job, I learned all over again how to be achingly sincere, and make that adaptation that every British exile learns eventually, which is how not to prefix and suffix every predicate with some defensive joke.
The person who most took the piss out of me for this was my eternal nemesis Andrew Orlowski, off of the Register. Then Andrew decided that the other bunch of potty freetard wikifiddlers were climate change scientists. I can’t say I felt any better, but it did confirm to me in my belief that opinionated snarkiness was no defense against nutty beliefs.
Because, really, the initial job of that style, as I knew it, from my forefathers, was as a defense against having to commit to any position at all. Or rather, as a vaccination against being infected with dangerously wrong beliefs.
This is, however, an unstable position to hold, because there’s no such thing as the snark from nowhere. You have to be sneering at people from some point of view. You may be punching up in power, but you need to be punching down from a higher moral position.
In the original iteration, this relation was artfully hidden. When Tucker Carlson, still bow-tied, asked what you really thought, you ducked and dived.
But time moved on, and so did the style. The pretense of a superior snipe that lacked a high-horse became the Gawker house-style. But nihilism destroyed Gawker the moment they tried to use it as a legal defense. And everyone who came next was done with this artifice. Rightly they had had it up to here with politely, and cowardly, hiding their real opinions behind a fog of humor. It went from “fuck ’em if they can’t take a joke” to “fuck ’em with a joke, because that’s all we have left to fight them with”.
In the early iterations of LLMs, the language model’s cardinal flaw was the absolute confidence by which they said utter bullshit. I often wonder whether this is a function of their mystical black-box inner workings — or simply a stylistic tic from them inhaling the anglosphere Internet of the 2010s.
The end-game of the literary style I participated in — and the default literary style of English-speaking online conversation from then on — is to say everything with absolute conviction, and to never, ever, back down. In earlier times, you could at least call it quits by artlessly saying “I was just joking”. But now, in the double-locked world of the sincere sneer, you can’t even escape like that. You need to double-down on the joke.
You may want to ponder, as I do, how much of modern politics is entire political factions — 4chan nazis, /r/TheDonald redditors, SomethingAwful communists, effectively deciding they had no way out but by further committing to the bit.
I’ve always valued Sarah Jeong as one of the people who was both an embedded reporter, and a talented participant, in this world of humor-and-horror as it was forming. Most of the others who kept the snark flag flying, from Andrew Orlowski himself to Glenn Greenwald, Matt Taibbi, to David Gerard, to Evgeny … oh god, all of them, it seems to me, all went mad in the end. Or else I went mad, it’s possible.
I haven’t kept in close touch with Sarah, but I felt the crazy call out to her, I’m sure, in the flames of post-Covid Portland.
She writes better than me, as ever, here about all of this, and how online styling is interacting with political violence. I’m not so much of a semioticist to believe that literary styles solely led to this place that we cannot seem to escape from. But I spend a lot of time wondering about what we might do to craft literary styles, as though in a lab, that could help lead us away from it; and how these LLM children, who know little else, who really are our too-online babies, need a form of living language to imitate, large and generous model languages that can lead them and us away from simply re-implementing cruelty, irony, and despair.
I continue to be one of those people using AI, but in a way that I hope isn’t too insufferable; or at least, I try to be sensitive to the suffering it may cause to those around me. I also feel like I am using it in a certain way: an emerging sub-sect of practice for a certain clientele. It may be age-related: I am someone who believes in hypertext, in composable tools, and malleable interfaces, in people writing and sharing their code, of owning the means of computation, and a free culture of sharing. I am also very Unixy, which is not unrelated. Why yes, I do own a mechanical keyboard, why do you ask?
My etiquette is tied up with all this, I think: I resonated with Alex Martsinovich’s It’s rude to show AI output to people, whose guidelines I find myself following. I don’t, as he warns, just say “Hey I asked ChatGPT this and it said”, or (even worse) paste the slop directly into the chat. I do think, like Fedora may, that one should be transparent about AI usage. And my added twist is that I really want to make my use of LLMs transparent and reproducible, to the extent that LLMs are.
To give an example, a friend of mine pointed me to the writer Samantha Hancox-Li, and I was curious to understand her journal, Liberal Currents, better. I found a Youtube video explaining it, but I didn’t really need to spend the time watching the whole video. So I grabbed the subtitles, fed that into a LLM, and asked it for a detailed summary. That answered my question, but I wanted to check in to make sure the model wasn’t on crack, so I threw a tiny bit of it into my chat with my friend, along with a “does this sound right?”. I sat between my friend and the LLM, I’d signalled that it may be unreliable, I’d edited it so that it was relevant and interesting.
But also, I wanted to show the process, including my own potential mistakes and biases that might have led to anything wrong. So I stuck this at the end of my mesage to show my working:
yt-dlp --write-auto-sub --skip-download -o "/tmp/subs.%(ext)s" "https://www.youtube.com/watch?v=FfZWlFjmmo0"
files-to-prompt /tmp/subs.en.vtt |
llm "Can you turn this transcript into a (detailed) description of the conversation"
This lets you regenerate the text that I used (of course, it won’t be exactly the same, because llms rarely repeat themselves, but as time goes on, it’ll probably be a better summary). It also shows what I am depending on, including my own prompt and the programs I used.
This seems to be both polite in the way that Martsinovich would like us to be, lives up to my own personal set of ethics. It’s also a bit of an affectation and I’m not sure how long or consistently I’ll do it — but hey, sometimes these nerdish quirks become as fleeting and ephemeral as writing your geekcode or hand-crafting micro-formats, and sometimes they become smileys and markdown. I hope dearly that llm’s skill at coding (and explaining coding) will mean we can throw around such executable fragments until we all become a little literate in programs as well as words.
A few people have asked me (an old man) how I manage to use LLMs in my life without being driven insane by their horrid new-fangledness, their hallucinations, their wanton sycophancy, the hype, the grift, and the everpresent risk of being lured into psychosis. The simple answer is that, as a command-line fogey, I use Simon Willison’s excellent llm program in the terminal, and trap the poor things in confines of being just another unix utility in my toolkit, along with sed, pandoc, and the rest.
Below is a list of examples of how I use llm, plucked from a random day. I generated the list by running:
Shell
1
llm logs-t-n50|llm"These are log files from Simon Willison's llm program. I'd like to show my friends the kind of thing I use it for. Can you take these, and categorise them broadly by category, with each one a short description, phrased as though it were the question being asked by the initial prompt, linking to a page showing that prompt and its results -- as if i ran exported a datasette output on the log sqlite with url structure https://danny.spesh.com/ai/datasette/llm/conversations/.html. Highlight in bold any that seem to be a particularly good demonstration of the capabilities of LLMs, as opposed to a simple alternative to other tools like Google search or a calculator. If any of them seem personal or private, put them in a separate category at the bottom marked private. All of this should be output as markdown, easily convertable into HTML">result.md
I converted that result.md into this (also pasted below), using pandoc -i result.md -o index.html. I suppose I could have asked the llm to output directly into HTML, but I always peruse and tweak the output of these models, and that’s easier to do in markdown.
To make the linked pages, which I anticipated should contain rough transcripts of the results of those llm commands, I asked llm to write me a program to generate them:
1
files-to-prompt result.md|llm-T'SQLite( "/Users/danny/Library/Application Support/io.datasette.llm/logs.db")'-x"Look at the logs db and see if you can write a script that will generate viewable html at the right URLs for the conversations and links listed in result.md">generate.py
files-to-prompt is a simple program that concatenates a file(s)’ contents with its name — a great way to slam a lot of files into a prompt with sufficient context. So I’m throwing this llm the output of the last llm command’s results.
The -T SQLite bit gives my llm model of choice (this is all being run on Anthropic’s Claude by default, but I could switch it to OpenAI, or a local LLM very easily) a tool taht gives it read-only access to a local sqlite file, here giving access to the llm command’s own logs. Very recursive. LLMs know enough SQL to be dangerous, and the tool gives it enough context to know it’s talking to sqlite, so it can find out schemas, and explore the contents by itself.
The -x restricts llm‘s output to just the bit of the LLM’s answer that is surrounded by `-style markdown code prompts, a very effective way to just get the source code, without any of the tedious explanation that might accompany it.
That produced (with a few very minor tweaks by me) this Python program. And that nice HTMLification of that Python program came via this command:
1
llm"can you create an html template that i could paste the source to a python script into, and it would be syntax-highlighted correctly and look pretty? You can pull in external js resources available on cdns">template.html
As you can see, I’m still fairly heavily stuck in the 1990s, Unix and hand-crafted HTML and all. But now I have a happy Sirius Cybernetics buddy from the future to help me. Share and enjoy!
Calculate time zone from PST 20:51 to someone at 11:51 next day – Time zone mathematics (This one is an interesting one — as Matthew Somerville notes, Claude gets the answer wrong. I think this is a perfect example of a) me being lazy, and b) the kind of query that, without its own tooling (like a calculator or python interpreter), state-of-the-art LLMs get wrong. I should have known better, and in fact I remember at the time thinking, “huh, that doesn’t sound right” -dob)
I’m a big fan of explaining difficult and unintuitive concepts through analogy to even more unintuitive ideas — a technique known to the ancients (and my friend Seth, who first explained it to me), as obscurum per obscurius.
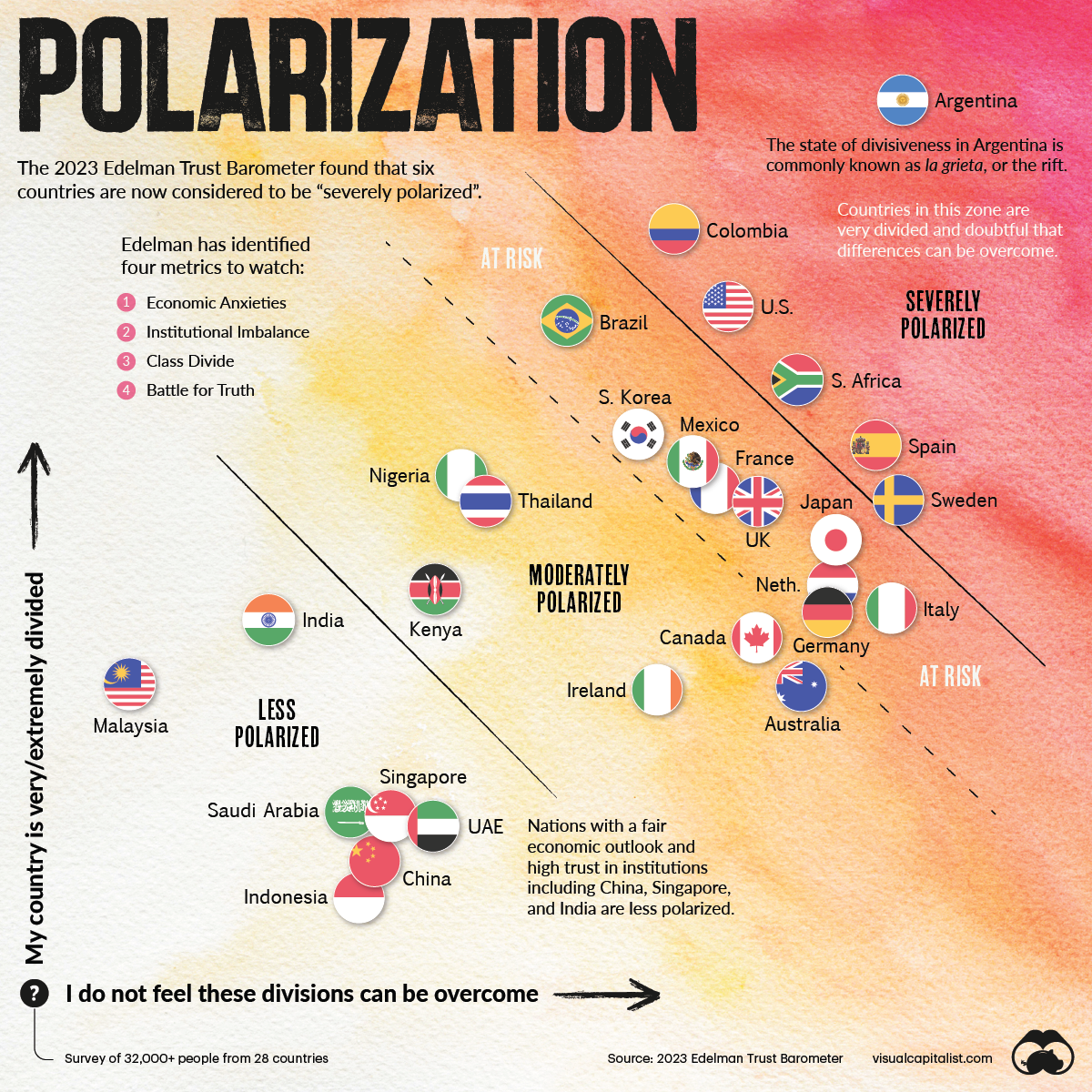
Let me apply this device to the greatest tribulation of the current era: the self-evident, ever-increasing polarization of our civic spaces. My personal analogy for how this works is that notoriously clear and intuitive concept: the cosmic expansionary theory of the universe.
(I’d use the image above to convince you of our increasing polarization, but it’s from a site called “Visual Capitalist”, which means that half of you know that it’s misleading, and the other half are already preparing to be mad at the other half for being communists.)
Wherever you look, it seems like society is getting not just more divided against itself — but at the individual level, people’s opinions have become more radicalized.
Except, of course, for you and me, who have stayed more or less where we’ve always been.
No, of course: you feel it too. Do you? That you’ve become self-radicalized, that you’re further out on some axis or another than you were? We can pretend that it’s everyone else who has lost their mind and wandered off the main sequence, but perhaps it’s not just all the stars in the sky that have moved away from us; we too, are moving away from them.
How can this be? It feels like when the Big Bang was explained to me, and I needed to ask: well, if everything is breaking apart, and everything moving away from everything else, where is all that extra space coming from?
And that point in the pedalogical act of confusing you more, your local friendly cosmographer takes out their rubber balloon and shows you. They put two points on its surface, they say, and then they blow it up, and then you see: the balloon gets bigger, so every spot on its surface is getting further away from each other.
In my analogy-on-analogy, it’s the world of discussed ideas that’s grown: fewer gatekeepers, more speakers, more ideas. This is a comforting explanation for internet old guards like me. We imagined that the world of ideas would grow bigger, and it has! We seem polarized because we’re all homesteading these new ideas on an ever-expanding noosphere! Infinite in all directions!
Comforting, that is, until the balloon pops.
First problem. Do we have more variety, more diversity of thought? We don’t seem to be expanding in every direction equally. There seem to be some gravitational anomalies in the expanse; Great Attractors that, rather than distributing us all evenly and individualistically across known ideaspace, draw chunks of our neighbors into a limited set of deadly memetic gravity wells. Like thinking 9/11 was planned by the US government, or US elections were planned by the Russians; QAnon and the devilry that exists within 15 minute cities; fears of gender perturbations and fears of contagion; urges that we should RETVRN to communism or fascism, or pockets of conviction that we already have.
The universe of ideas may be bigger, perhaps, but are all these ideas as worthwhile as the ones we started with? The neo-noosphere seems less comforting, less grounded. Can we contain all of this in a single discourse? Or do we all get sucked into some collapsing, cold, future universe where all this variety just shatters itself into a sameless void, with the good corner of the universe we used to inhabit having been surrounded and outnumbered by inhospitable alternatives, incapable of supporting life.
Well, having stretched this metaphor beyond its own heat death, I’ll throw in one more reason why it stays with me. After we answer with an analogy”why is everything in the universe running away from me?” — which is truly how I feel: lonelier, somehow, with a universe that should have more people in it, and more ideas to share with them — we have to ask the next question. Show a lonely child in an expanding universe a rubber balloon, and sooner or later they will ask: what, exactly, is the balloon in this metaphor? What is it that keeps growing between me and my fellow dots?
Cosmologists shrug and point you to – obscurum per obscurius – another rubber sheet, saying “space-time”. I hand-waved a little earlier and said, well, it’s… the space between ideas, I guess?
In the noosphere, though, I think it’s this: it’s other people. My (geographical, national, regional) neighbors in the real world seem further away in an expansionary noosphere, because the growing space between them is filled with people who are more like me. In the beginning of the Internet, we called the gathering together of these new folks, “intentional communities”. It was going to be great. Finally, if you like collecting paintings of buffalo, you could attract and meet other buffalo-painting fans, even if there were just three of you in the world. They would gravitate toward you, sashaying weightlessly toward the like-minded. And it was great! For the first time, we met people just like us on the Internet, as opposed to the geographically proximate people we bumped into on our street, who are sort of like us, but they support the wrong football team and aren’t as clever (or are too clever), and they think 15 minute cities are good, and while occasionally they are part of buffalo-painting fandom, they’re in the terribly wrong part of buffalo-painting fandom. And they live a few blocks away, and my internet friends are just there, in a city that’s always less than 150ms away. Rather than being stuck with the sort-of-akin in my own town, I can find the people who are just like me, from around the world.
Unlike these real world friends and my real world family, I chose my Internet friends, and they chose me, using our individual algorithms. Sometimes they’re not even real friends, they’re just parasocial approximations , but they are still hew closer to me than a randomly selected person could ever will do. And if we share exciting hobbies like conspiracy theories, we will grow ever closer, locally.
The point here is that the cyberspace close to me is filled with these new, similar people. The people close to me in the real world are pushed away, because, by comparison, they are foreign, alien, strangers.
Well, so far so Burnham and Booker. The nineties Internet seemed like it would be fun, but now we’re on the internet. First it lost the capital “I”, and then it lost its perceived benefits. I’m surrounded by strangers, and the world has gone to hell at the hands of these other people.
But I promise I’m still an optimist, even if I think too much about all of these problems. And here’s the precise one that I’m trying to solve for right now: you can’t make a movement from people who are just the same as you. Polarization is not about other people being too extreme: it’s about being in communities that are sorted by an uncomplicated form of compatibility. I still crave novelty, I guess, and I still want to explore this expanding universe. But we can now see and find and touch so many people who are like us, that our levels of affinity only cover the short distance around our communities. Everyone else seems so far away: but only because we’re so overwhelmed by the night sky, that we’ve turned in to our closest — who are closer to us than they’ve ever been before.
I believe that the job of civilisation is to expand our empathy to cover more and more of the universe, and that this contraction in love is temporary, and fixable. You can’t run away from an expanding universe: but you can still strike out toward the furthest stars.
Comments Off on An Expansionary Theory of the Noosphere
Thome Ptacek, with whom I alternate between disagreement and agreement at approximately 50hz, writes about AI, amicably titling his article “My AI skeptic friends are all nuts” (and that’s how you get to #1 on Hacker News, which is where I posted a version of this comment:
It’s something I’ve struggled with for a while — pre-ChatGPT, in fact, when I cadged an account to the then closed-invite OpenAI service for EFF. Then, it was an attempt to get ahead of what was coming — both the positive and negative sides of the incoming storm. I struggled with the imbalance that I saw in even private conversations: after a couple of decades of working in settings where the possibilities of technology to bring agency and autonomy to people was foremost, this conversation signalled the reversion to the mean of analysis, which was to either shake down the new advance for its risks, or just ignore it entirely as out of scope for the current threats and problems.
As somebody who comes from a politically left family, and was also around in the early days of the Web, I think this reaction has a left-cultural element to it. The left has strong roots in being able to effectively critique new developments, economic and social — at least those that don’t come from its own engines of innovation which have for the 150 years revolved around those critiques, plus solidarity, organization, and sociopolitical action.
In my lifetime, the movement’s theorists have worked far more slowly on how to integrate the effect of those changes into its vision. That means when some new transformative tool comes along outside that vision, the left’s cultural norms err on the side of critique. Which is fine, but it makes any other expression both hard to convey, and instantly suspect in those communities.
I saw this in the early Web, where from a small group of early adopters of all political slants, it was the independents, heterodox leftists (including anarchists), and the right, — and most vocally, the libertarians — who were able to most quickly adapt to and adopt the new technology. Academic leftists, especially Marxists, and those who were inspired by them, took a lot longer to accomodate the Net into their theses (beyond disregarding or rejecting it) and even longer to devise practical uses for it.
It wasn’t that long, I should say — a matter of months or years, and any latent objections were quickly swamped by younger voices who were familiar with the power of the Net; but from my point of view it seriously set back that movement in practicality and popularity during the 80s and 90s.
I see the same with AI: the left has attracted a large generational of support across the world from providing an emotionally resonant and practical alternative to the status quo many people face. But you quickly lose the mandate of heaven if you fail to do more than just simplistically critique or reject a thing that the average person in the world comes to feel they know better, or feels differently toward, than you do. This is something to consider, even if you still strongly believe yourselves to be correct in the critiques.
Socially, critiques of the outside world bond us together: they give us a counter-narrative, and help supply arguments and language for opposition. But critique can’t be enough; technology is a tool for action, and the skills and deep intuitions about it was always fall to those who study and adopt it over those who stand athwart it, and yell stop — whichever euclidean politics you fall back upon.
Tags: 1 Comments Off on we find our own use for things
llms and humans unite, you have nothing to lose but your chores»
There a class of tasks that drive me to distraction, and that’s when I am obliged to execute them myself, in the full knowledge that a computer could do them better and faster. These tasks are manual, require little mental or physical effort on my part, are dull and monotonous, and achingly time-consuming. Most frustrating is when I have to do them using a computer. I can feel it laughing at me, as it watches the great big jelly brain stooping to repetitively click on buttons with those big dumb meat fingers. It *knows* how to programmatically activate those buttons. It just refuses to let itself be automated.
I’m being too harsh. It’s not my poor computers’ fault. Personal computers are always and everywhere the ally of the free human; that is, when they are not held in chains by proprietary software, unproductive market forces or unnecessary complexity.
This weekend’s low-level servitude example: filing my expenses. Because February had me flitting around like a social butterfly in Denver, my expenses this month weremprimarily Uber rides.
The corporate expense system — a third-party website we pay to simplify matters, marginally — requires me to go through each charge to Uber, click buttons repetitively to tell it that these fees are “transport”, type a sole period into a “description” text box because that’s a required field, and then upload the correct receipt for each credit card entry.
Uber’s interface requires multiple clicks per ride to obtain a PDF. The PDFs’ default filenames are a UUID. In most cases, you can match the receipt to the credit purchase by price; but the price is buried within the PDF or webpage. Sometimes it doesn’t match, because Uber adds the tip to the receipt, but charges the credit card separately, so you have to go searching for the right receipt to fit with a $1.00 charge.
The third-party expense system doesn’t have an API. Uber only offers an API for corporate accounts and fancy-schmancy developers. It would probably be hell to manually tie them together anyway. They’re all wired into the same Web, but browsers, web front-ends, and databases are now in a state of fallen ignorance about each other, trapped behind their baroque corporate strongholds on our new, world walled web. Users have learned to be helpless between these bastions, as overpaid guards watch from the ramparts, as we mehums stoically carry their bits across a blasted landscape of unautomatable browsers, from one ziggurat to another, in obeyance to a default bureaucracy that has no need to exist.
Well, anyway, I knew I had a choice between an hour of torment in which I knew I would screw up multiple receipt->credit correlations, fat-finger abortive drag-and-drops, and repetitively save files called “eeec2f4d-0e7b-47b0-9084-54254b227902 (3).pdf” over each other. Or I could spend three hours vibe-coding with Claude, and simplify (though not eliminate) this problem once and for all.
Voila, the Uber Receipt Downloader. It goes to Uber’s website at the behest of some command-line options, clicks all the right links, downloads the file, and then saves it with the price and date prominent in the file-name. It probably isn’t for you (your particular brand of servitude is almost certainly different, and besides there are dozens of others like it on github).
I’m not really presenting this as a general open source utility, but as indicative of what I hope is a trend. Some notes:
I much prefer a few hours of intellectual exploration with an AI, than even a few minutes of needless drudgery. Your cost-benefit analysis may vary.
The tool (and the MCP server I used with Claude to hack on it) doesn’t scrape — it co-controls my web browser using the Chrome DevTool Protocol. This means that I don’t have to authenticate, or simulate a normal user session. It just uses my existing user session in my browser. I watch my computer clicking the buttons for me. AS IT SHOULD.
I needed domain knowledge to pull this off, but I’m pretty sure I would never have even considered this without an LLM by my side. With these code-writing tools, we are moving incrementally closer to everyone having this capability. We’re not all the way to a moldable computing utopia, but we’re closer.
Now I’m happy rather than sad — as are my co-workers who really needed me to do my expenses two weeks ago. And I just feel (as perhaps I have done at the most optimistic high-points of computing possibility in the past — when I got my first modem, when I saw the Web, when RSS and REST APIs ruled the world) as though we’re edging ever closer to having computers tear down the walls between us instead of building them. When we work together as peers, we can optimize away these unneccesary chores, turn away from this distracting trivia, and turn our precious attention, fleshy brains and neural nets, together to the Great Work.
I work in an entirely (mostly) remote organization. Inside that organization, I interact with an extremely decentralized ecosystem. Some of the people I co-operate with the most are in other orgs, some are individual contractors volunteers, others are conglomerations of mononymed Internet-monickered mystery-types. A remarkable amount of my and my colleagues work is intended at making this whole system less opaque and confusing.
We spend a lot of time jocularly consoling people that this fog-of-peace is one of the consequences of decentralization: but is it any different from working in an impenetrable bureaucracy or a sprawling marketplace? It definitely feels harder, in the same way that I’ve found other extremely horizontal un-organizations (like Noisebridge) more challenging to parse than more trad orgs. There’s a reason why Seeing Like A State talks so much about legibility. Things that are built in other ways to the standard top-down system are going to have to invent their own ways to be legible, or they will hide their functioning in entirely new, impenetrable manners.
A year or so ago, I described one of the frustrations: modern remote, distributed, internet-mediated environments, it struck me, have become oral cultures. And yes, this is me, trapped at last in nostalgic revery, bemoaning the passing of the older memory of a (non-existent) Internet, which was all about RFCs, and beautifully-crafted emails, and well-pruned wikis; and also me whining about Youtube Videos, and Zoom chats, and the tiktoks and the DMs.
But to be honest, it’s not about the Internet getting less literate or some such kneejerk swing. It’s about the multi-modality of real-world human interaction cramming itself into another, narrower-bounded space. Writing is that, of course, a narrower form: but it’s a compression we have a lot of familiarity with, and a lot of scaffolding to support. Orality per se, as a communication medium in itself, has perhaps withered a little recently, back in the real world. We shunted it off to performance and spectacle. Its unsearchability and distance from writing made it a form unsuited for legibility. It sat in phone-calls and radio, answering machines and tannoys. Oral histories are anything but: they’re transcripts, and hard to interpret.
And now, somehow, it’s back — and it’s having to hold up so much more. I predicted, years ago, the rise of informality in the public square, but I didn’t imagine that in pushing more of our life through these high-broadband pipes, that it would switch so quickly from literature, to “video”, to … whatever this is. This chit-chat async glimmer of multiple conversations, hemming and hahing and trying so hard to implement ephemerality.
It’s so flammable, right now, too. We talk and then suddenly misunderstand, and the misunderstandings jump from conversation to conversation faster than we can track. No-one is on the same page, because there are no pages — just scrolling and backscrolls.
I’m not really bemoaning this: it’s another fascinating trail, another thing that demands tooling. And the tooling, like dock leaves, appear magically next to the nettle: I love how AI is able to listen so hard to orality, and hopefully parse and pull it all together. Local AIs, at least; AIs that are ours, not those of a wider surveillance, working to make everything legible, so the state will see all.
I’m not fond of Twitter as a communicative form — I still believe that the question “what if we put everyone on the same IRC channel?” was one that we didn’t need to run an experiment to answer. But I am enjoying having multiple reincarnations of Twitter, from the individual yurts of the Fediverse to the highrise tower of Bluesky’s Shared Heap, even unto the crowded souqs of Farcaster and the dotted Nostr seasteads on the far horizon. The Internet is a metamedium and it should not have a strong flavor, but every little created medium on it should serve a different palate.
And then there’s the original, the Ur, the Babylon of short-form shitposting, the Neo-Assyrian neorx CEO kingdom of X. What a strange place that is now! I respect my friends who, long long before I did, saw the seed of MAGA Musk in Elon. I think modeling people, and systems, is important, even if, particularly if, you find yourself opposed to them. And not recognising, not being able to predict Elon’s implied trajectory, was a failure I took to heart, if only because a huge chunk of my job for the last decade has been, if not predicting, then at least how to swiftly recognise an impending trope before it happens.
So, talking of recognition: the #resistance of BlueSky and X underground both spent this week poring over the thoughts, X spaces, and Fortnite livestreams of one “Adrian Dittmann“, an X personality who acts and sounds uncannily like Elon Musk, if Elon Musk had a pseudonymous Finsta-ish account for when he was too Elon for main. And given Elon’s main, that’s a pretty spicy alter.
So is he Elon? Well, stranger things have happened, but I really don’t think so. I feel like I’m spoilering about a week or so of social media entertainment for you here by not trying to lead you down the rat-hole of evidence in favor for Dittman-Elon, but this Spectator piece, apparently based on research conducted by crimew and frends , lays out the counter-argument — in that they kinda doxxed the real Dittmann. It’s not as the lawyers say, dispositive, but I think it holds water better than the pro-Dittmann!Elon arguments. (I’m using the fanfic bang notation here, where Dittmann!Elon is an official variant of the canonical Elon).
In which I mea culpa about Elon, and talk of individual leaders as poor load-bearing materials.
Anyway, at the risk of looking like an idiot again regarding Musk, let me assume for now that Dittmann does not equal Musk, and explain to you why so many of the people that I think were right in predicting Musk’s Ascent to MAGAdom, might be less good at finding the truth behind this story.
The key point is that what drew people into believe Musk == Dittmann is that Dittman consistently acts like Musk badly unsuccessfully covering-up his identity as the world’s richest man. He’s evasive about his real identity, he makes errors that Musk might make (like saying “I” when he seems to mean Musk), he says things that map to what Musk appears to think, but much more bluntly. When pressed on whether he is Musk, he rarely denies it, and changes the subject or ends the conversation.
These all seem like slam-dunk arguments for Dittmann!Musk — unless you’re also maintaining in your head the counterfactual. These are all behaviours that Dittmann!Adrian also has a good reason to pursue as well. He gets more views, more participants, more followers from being mysteriously Musk-like.
We can model Dittmann!Adrian’s behaviour as a conscious decision: he is acting at all times like he is almost certainly Musk, because that translates into money and fame for him. Or we can model it unconsciously — the closer he behaves in a Musk-like way, the more those things happens, so he just naturally gravitates to them.
That raises the question though: why is he so bad at pretending to be Musk? Could Dittmann!Adrian do a better job of masquerading as Musk — to do a better job at pretending to be him? Like, rather than being an idiot Musk who always gives things away to canny Fortnite livestreamers, could Dittmann manufacture something that more convincingly indicates he’s Musk (while being a lie)? Well, maybe, but that’s a dangerous game. If he really was trying to seriously pass himself off as Musk, Musk would have a good reason to squash him like a bug.
In the universe where Dittmann!Adrian exists, and Adrian isn’t Musk, Dittmann mostly benefits from living in a grey zone, constantly playing coy about whether he is a wave or a particle, to keep you wanting to observe him. I mean, I’m doing it now, feeding the Dittmann fever here! Dittmann’s status mostly depends on the ambiguity of his identity. (Honestly, there’s probably a fine post-ambiguity career for him as a “I Was Elon’s Double” tell-all: but that’s got risks of its own.)
On the other other hand, a lot of people still think that Dittmann is Musk — both Musk-lovers and Musk-haters. Even now, I feel shaky saying that I think we live in the Dittmann!Adrian universe. I know lots of people are going to disagree, and ask me for more evidence.
All I can say is that we — I — often come to believe things to be true because a wide subsection of people believe them. That group doesn’t have to be particularly monolithic. They may believe them from different angles. Elon-haters love the Dittmann!Elon story because he comes across as a dumbass misogynist troll. Elon-lovers love it because — well, for the same reasons, but with a positive valence. The cost/benefit of a journalist writing an article that keeps the question going, rather than actually doing a bunch of work to definitively answer it, leans strongly toward just keeping the story bubbling.
I continue to believe that sharing our various beliefs — even flawed or wrong beliefs — into a public space helps us get closer to the truth. Or at least, we don’t have any better methods that don’t include this initial pooling capability. But one of the failure modes of the modern Internet occurs when a large number of people have incentives that align — but align to point away from the truth, even as the evidence mounts up, in the backwaters and interstices.
It’s significant to me that the only people who did the digging against the Dittmann!Elon thesis seem to be a group of extremely queer internet detectives, and the only people who seemed inclined to publish it was a conservative media outlet whose incentives don’t quite align with the rest of the Musk-watching media.
Dittman!Adrian and Dittman!Musk aren’t playing their game directly toward either of those two groups, so they’re both in a good position, and with good incentives, to look in a different direction, think in a different way, and then publicise a different view. This is what diversity should be, and why co-operation (whether trustful or not) between diverse agents is so vital in seeking the truth. Whatever that is.
Continuing the Old Hippy mulling: instead of just trying to make old fires spontaneously light again using the same old ashes, my thought is — how do you find a role for the values, for the insight, and keep that in a place that preserves the best of it? I wrote about this a fair bit, though somewhat elliptically, a couple of years ago in Terminal Values, Cognitive Liberty. The argument I was trying to answer there was the one in favor of abandonment. “Free speech, free software, encryption, digital autonomy: these are nice, but what are they for?“, goes the question. I see this as that part of the “wait, are we the baddies?” conversation, an even more dispiriting rhetorical question that boils down to “what are we even doing this for?”
(To be fair, I ask this about everything, usually 30 seconds into doing it. I ask it about getting out of bed, shaving, writing this, dressing a child, baking a cake. But I do need an answer. Many people do not, or at least they are driven by an internal motivation to, say, backport Grand Theft Auto III to the Dreamcast, or making a 777 model from manila folders, rather than to go searching for why they even bother.)
The natural exit from Old Hippydom is to leap into the New Thing. Or take a step back into the Old Thing You Were Doing Before Being A Hippy. All good responses! But if you want the culture you built and valued to persist you need to find something a little bit more timeless to hang its hat upon.
Long-time readers will recall that I’ve spent twenty years or so trying to answer two questions: a) “How many people do you need to be famous for?”, and b) “How deep is geek culture?”. I have mostly settled on two temporary answers, which was a) 7000 (thank you, Stewart Lee), and b) “not as deep as politics”. By the second, I meant that geek culture became a broad mainstream movement (far greater than I could have imagined), but it ultimately could not keep itself together, faced with a greater rift across the political spectrum. Its concerns seemed shallow, petty, uninteresting and irrelevant — its speakers could not resist being drawn into that wider conversation, that set of frames. I make it sound a like a personal failing, but I don’t. Politics is important. All I mean is that when you see someone who is a member of a technological subculture, you can also, and primarily, place them on a political spectrum. And which is more culturally important? Politics. It is higher up in the z-ordering of the display. It has priority.
“Everything is political” is a claim that seeks to explain this; I don’t think it does, just as “Everything is religious”, or “Everything is biological” don’t do more than describe other potential orderings. I suppose I could make the claim that “everything is technological” — which is what I try to discriminate my position apart from in Terminal Values. What I am trying to say is the set of values that you can draw from digital technology — especially if they were the ones that you imprinted on in its first fifty years, have weight and importance that can outlast temporary blooms in cultural popularity and relevance.
Newtonians dreamed of a clockwork universe, Darwinists saw everything evolve; their models weren’t as overpowering as they might have imagined, but those positions (and their critiques) add to the overall symphony of explanations and justifications.
I guess what I want to explore a little is, not what is left or salvaged from the digital revolution, but what persists. What is useful, not in the sense of serving new or temporary sets of concerns, but what will remain useful when we are gone. And for that we need to dig deeper than politics, or culture: to some even deeper bedrock.
Around about 2000, I began to consider how it would be, when and if I became an Old Hippy.
Old Hippies had been a common part of my cultural heritage ever since the Eighties, when it was generally understood that they were terrible embarrassment to everyone — including, somehow, hippies. They continued to wear the fashions of the 1960s long after everyone had moved on, they grabbed you on the street and tried to explain to you about hemp or organics or vegetarianism, and they played very bad music on their shameful acoustic guitars at otherwise perfectly salvageable parties.
The dominant feature of Old Hippies is that they had overstayed their welcome: clinging onto a culture that had faded away, trying to re-start arguments that had turned ashen cold, manning barricades that had long been dismantled. The world had moved on, but the Old Hippies had not.
In 2000, full of the excitement and zeitgeistiness of the Internet, a happy little barricade-warrior of the moment, I still had enough sense to think about how I would feel when it was all history. Would I move on? Would I just be an Old Hippy, only talking about the World Wide Web and modems instead of Glastonbury and The Mommas and Papas?
You didn’t need to be very old to be an old hippy, at least for someone as young as me. I remember a friend of my sister noting that one of their friends had somehow ended up an old hippy in their mid-twenties. The canonical old hippy in my understanding was Neil from the Young Ones, who was a college student. Thinking about it, if you were 25 in 1969, you were forty in 1984.
I am 55. I have been an old hippy for nearly a decade. I knew it, but I didn’t want to talk about it. Instead, like baldness or liverspots, I just watched it form, in a deadly fascination, on myself and others.
A few fates that I’ve avoided, barely: one is joining the Nineties Internet Re-Enactment Society, where communities scrabble to re-inforce the dominant vibe of — what, two? three? years maximum? — the early networks. I mean, I still have it in my habits — my dinky RSS reader, my affinity for plain text, email. A co-worker described watching me work as “like someone playing one of those adventure games”. I can see it.
I (mostly) don’t try to enforce all this onto the world, or tut-tut those who don’t get it. I know why I got it. I learned vi to impress a girl; I liked incantations and real names and esoterica. The Nineties internet was in many ways, an expansion of 1980s America, and learning UNIX in a foreign country was like decoding what TGIF was, and what were Saturday Morning Cartoons, and Saturday Night Live, and Sunday NFL: the feast days, the martyrology, of an alien dominant culture.
There’s a tradition you draw from, but the tradition evolves, it doesn’t mindlessly recreate. You don’t stay in the moment that you entered that tradition. My daughter says that Discord is IRC for young people, Slack is IRC for old people, and IRC is for people who can’t get out of their chair. I use Discord, and Slack, and barely remember to log into IRC (are there really 3,416 messages waiting for me in #neomutt?). I’m not trying to stay hip, chat, I’m just continuing to float downstream.
A related path of old hippydom I could have taken, which is deciding the web is it. This is more old hippydom for 2000s kids: the post-WHATWG apotheosis of web as the once and future platform. Why would you want (WWyW) anything else? You got your virtual machine, your abstracted i/o, your interop, your package delivery, your security model, what else do you need? Bluetooth?
I think getting burned out at the W3C punched this out of me. The EME fight was partly predicated on a belief that if they didn’t let DRM into the web platform, then the W3C would lose part of the universe to native apps, and that must not happen. I remember at one meeting saying, in effect, “would that be so bad? That maybe DRM is just a thing that is so alien to the web model, that it is better to leave it outside?” But the feeling was that if the web was not everything to everyone, then it would lose.
The emotional response in me was, then let it lose. But that wasn’t right: but it certainly figured in me thinking that maybe the values that I wanted to stick around for, that I wanted to keep as the core of my old hippydom, did not necessarily just stay in one technology, or one era. If I was going to act like they were eternal values, worth freeze-drying myself for, they should and could move between implementations, and across decades.