I’ve been futzing around with LISPs. See how we say LISP like that, all in caps? That’s how I think of Lisp; it has this vague aura of pre-1980s aesthetic where capital letters where either teletype-obligatory, or an actual indicator of futuristic COMPUTER WORLD.
Case in computing is a funny thing, like a binary signal in the ebb and flow of fashion. When and why did Unix (UNIX™) shell commands adopt that lowercase chic? I still write my email address in lowercase, even on government forms that request all caps, out of a defiant alt tone — DANNY@SPESH.COM stinks of AOL, Compuserve, and doing it wrong.
Common Lisp, forged in the eighties, expected, like Lisp itself, to be timeless: Common Lisp has CAPITALS all over it. Not exclusively, though. I guess when you’re Guy Steele and you’re trying to bind together futuristic AI and McCarthy fifties experiments, smashing together upper and lowercase is the least of your temporal concerns.
Will upper case make a come back? MAYBE IT ALREADY HAS.
I love this articleby Christine Peterson about her coinage of the term “open source”, not just for the story (which I’d known about, but never heard in detail), but for the tone of the piece. It’s written in what I generally think of as “Geek Old Semi-formal”: this precise, slightly low-affect, somewhat wry tone that seeks to depict the maximum number of factual points, in a simple but almost shockingly accurate way.
In pretty much everything I’ve done, I’ve fought with the hellish triangle of being readable, entertaining, and truthful. Sometimes you end up flexing the absolute clinical truth for one of the others: for instance, I don’t really “generally think” of Christine’s tone as “Geek Old Semi-Formal”. I just made that term up on the spot. I didn’t quite confess that earlier, because it sounded funnier to imply I’ve used this name, even just internally, for years.
Compared to just describing the tone flatly, I did very mildly better on the entertaining axis (at least in my own mind), probably just as readably, but really not as true. (It was also easier to write — because a term like that is actually exactly what I need for a title. Great, I’ll paste that into the title box up there, and maybe that will become the hook for others who reblog this.)
Anyway, where was I? Right: so, actually honest documents are rare, mostly unentertaining and largely unreadable. We rarely optimise for the absolute truth, because either one of “readable” or “entertaining” is more immediately valued, and rewarded.
Geek Old Semi-Formal is readable and true, at the expense of some of the fripperies of language that we associate with entertaining speech. It’s this beautiful upgrade of technical writing to convey conversation, stories, anecdotes, and the communal trivialities of our lives.
As part of my Plan 9 binge (did I tell you about my Plan 9 binge?), I’ve been reading lots of old Unix papers, which all aspire to this style. As the New York Times said in its obituary of Dennis Ritchie:
Colleagues who worked with Mr. Ritchie were struck by his code — meticulous, clean and concise. His writing, according to Mr. Kernighan, was similar. “There was a remarkable precision to his writing,” Mr. Kernighan said, “no extra words, elegant and spare, much like his code.”
I don’t want to say that computer geeks got this from Kernighan; I think that there’s a wide set of folks involved in factual-seeking professions and hobbies that hold similar aspirations, and end up admiring and adopting the same style.
This morning, I opened a mystery package delivered by the “browsing ebay auctions at 3AM”-fairy. It was a paper copy of this February 1980 issue of MICRO: The 6502 Magazine purchased for reasons of unstoppable nocturnal nostalgia.
I think even the august editors of MICRO would concede that the writing skills of its contributors were pretty variable. The year 1980 seems to be a seller’s market for 6502 periodical literature: There’s a full-page advert pretty much begging for people to write articles. (They’re paying $50-$100 a page, too, if you want to go back in time.) But for me, that variability is just a great opportunity to watch the Geek Old Semi-Formal style fail and crumble in different ways. The feigned jocularity! The laundry lists! The science paper formalism! I won’t point fingers, but you can flick through this copy of MICRO to see for yourself the rich panoply of Geek Old stylings.
It’s also a style I really have come to enjoy in face-to-face interactions too. There’s just something deeply comforting about sitting and talking slowly and precisely with someone, each of you carefully constructing entirely accurate sentences with little overall variation in tone or pace. Especially by contrast to the usual chit-chat of slapdashing word-sounds together and slinging them out your mouth in order to fill time and show off, between gurning physical expressions and uncontrollable emotional explosions.
Not that it doesn’t also work for emotions, too. I think of all the times someone I know has flatly, compactly and desperately clearly conveyed their experiences: remaining calm, grammatical and short-sentenced even as the tears stream down their face, and their life fell apart.
I wonder, too, why I associate it with older geeks (older than me, for sure). It smacks a little of the repressed-fifties model of male scientist, though I don’t think of it as entirely gendered; in real life, it seems as strange on men as women. And I see people younger than me adopting it, often comically until they get it right. It’s definitely a bit on-the-spectrum—but I’m not on-the-spectrum and I use it, and aspire to it.
Well, now I’ve felt it so strongly in Christine’s great piece, I’ll start looking for it more, in words and in conversation. And now I have a name to call it!
I’m 48 years old now, and I’ve never learnt to drive. When I was 17, on a deserted street with big ditches either side, my dad and I discovered that I needed new glasses more badly than I needed to learn driving right then.And since then, the time has never seemed right. Brief windows of driving-opportunity have opened and closed around me.
For most of my twenties, I think the collective income of all my housemates could not have paid for a car, and besides, in London, where would we put it? In the sink with the dirty dishes? The move to California was the obvious opportunity. I figured somehow that it would be easier here, and that my people’s collective knowledge of stick shift might give me a head start.
My first American driving instructor simply didn’t believe someone as old as me could not drive. If you’ve ever seen Richard Herring’s Driving Instructor sketch, it was the same, but with a 70 year old J.D. “Boss” Hogg. “Don’t you even know how to drive?”
I suppose he thought that if he insisted I drive back from the car-lot, I’d finally snap out of my charade. He held himself in horror as I immersed myself in the role of someone who could not drive — only now I was improvising the not-driving extremely quickly and at random things within sight of the El Camino freeway. I think I was his cue to retire.
After that, I even avoided driving videogames. In 2010, I looked up a San Francisco driving school that specialized in fearful, phobic or just unnaturally old non-drivers. This instructor was much nicer, and would tell me inspiring stories of previous incompetents who had finally got it together under his guidance.
With his careful stewardship, I failed three times, the last time (I swear this is true) before I’d even pulled out of the DMV. The Californian provisional license actually expires if you fail three times, as if you were playing Donkey Kong or something.
Really, the only thing all this car-learning got me was enough to understand that car-driving is madly dangerous, barely within the capabilities of a baseline human to master. I’d sit in the passenger seat and watch the driver, like Ripley and the marines watched Bishop play the knife game.
At some point, I gave up my dreams of buying a pickup truck and claw back all rideshare debt I’d built up. Instead, I’d tell people that I’d chosen never to learn to drive. Basically, I said, at fifteen I’d anticipated self-driving cars and was just a bit out on the timing. I don’t think I really planned that far ahead — though I did believe as a child that tooth decay would soon be a solved problem, and declined to listen to a bunch of future unemployed doctors tell me to waste years of my life flossing obsolescent teeth. But I convinced myself of this rationalisation when autonomous vehicles began to be a thing. After that DARPA Grand Challenge footage, I knew I was never going to face my demons. I’d be carried to the doors of heaven by obedient robots.
I’m not entirely rejecting the idea I could learn one day. It feels kind of wantonly ignorant to defy learning to drive. Plus, I’m learning the ukulele, and it can’t be more difficult than that, right? Actually some of my new skills, like managing a chord change while not dropping the instrument, might even be transferable into the motoring context.
But mostly I’m getting pretty good at just accepting my fate, and taking a lot of cabs. Also, I found out on one of those shifty-looking, FDA-unapproved DNA analysis sites, that I actually have a gene which is associated with, scientifically, not being able to get it together in any physical activity more complicated than hopscotch. So if the carbots doesn’t pan out, maybe CRISPR will get me there, faster.
Comments Off on i am a passenger and i ride and i ride
I’ve started detecting one of those biological changes that no-one can quite prepare you for, even though their existence is almost a cliché: in this case, the increasing clarity and number of my early memories. In bed, trying to sleep, I can bring up for the first time in decades my old primary school, or the shopping center I’d walk to when I was six or seven. Names like Mrs Turberville, and Tavistock Road pop into my head. When I close my eyes, I move through Street View and View-Master imagery of where I grew up.
I’ve always moved, in largely increasing distances, away from where I was born. In 1979, when I was ten, we moved away from my birthplace of Basildon to Chelmsford. Then I went to Oxford, and spiraled around to parts of London, then gravity-assisted out to California in 2000. I’ve been firm all this time that I don’t want to go back. I’ves wanted to go onward, further, never stop.
I was pulled toward cyberpunk, fringe technologies and anticipated states. At Ford’s research center in Basildon in 1977 or so, I looked wide-eyed at a vector graphics depiction of a stick man jumping on a rope. I’m staring in the dark in a long wooden garage or shed behind a chip shop, clustered around Eugene Jarvis’ Defender, newly arrived in Essex. I’m sitting in Dave’s room at college, reading William Gibson for the first time, around 1987. They all pushed me away from my current location, into the future, into unexplored space.
But my imagination about what forward means seems embedded in the origin, much more than I thought. The first joke that I noticed being played on me was in 2000, when Havenco, the short-lived cypherpunk offshore data haven, opened a few miles off the coast of Felixstowe. If only I’d waited, I could have caught a bus from my hometown to an arcology of sorts. Then I found out that the current wave of dystopian futurism, was being spun and incubated by Warren Ellis, who had stayed in Southend to wrote of the future city of Transmetropolitan. I would have been closer to my fictional vision of the future (undisturbed by reality) in Essex than in San Francisco.
I’m more comfortable now that I’ve just been chasing bright shapes on the horizon that were always being projected from just behind me. Perhaps it’s because that past, hidden behind my back, is now coming into easier focus
My latest foray is a reading as much of Colin Ward as I can. Colin Ward was an anarchist, whose writings I’d never before read, but who was born twenty miles from me. He loved to write and think about the New Towns, the planned communities build after the Second World War. One of them, Basildon, is where I was born and lived until I was ten. It’s always been one of the places I’ve imagined myself running from — and I’m not the only one. When I grew up, the New Towns were a running joke of austerity and dismal modernism, horrible sink estates for the working classes, where they were locked out of newly profitable cities, and made to fend for themselves in barren housing and an unsympathetic paternalistic “development corporations” that planned and ran the city with technocratic disdain. It would be a throwaway line of mine at Oxford to confess my roots. No-one was snobby about it, but I had no interest in defending the place.
Colin not only looked for the good in the New Towns, but also saw it under the substrate they were built upon — the sheds and trailers of an older pre-urban Essex that were homesteaded by Londoners so unhealthy and desperate that they’d rather set up a tiny home with no electricity or hot water than and grow their own food, than live off tea and tinned peaches in the slums.
These were the plotlands. Here’s Colin’s description, plucked from the comments of a site devoted to the even more obscure corner of Basildon I was born in, Laindon:
“In the first half of the twentieth century a unique landscape emerged along the coast, on the riverside and in the countryside. more reminiscent of the American frontier than of a traditionally well-ordered English landscape. It was a makeshift world of shacks and shanties, scattered unevenly in plots of varying size and shape, with unmade roads and little in the way of services.
To the local authorities (who dubbed this type of landscape the “plotlands”) it was something of a nightmare, an anarchic rural slum, always one step ahead of evolving but still inadequate environmental controls. Places like Jaywick Sands, Canvey Island and Peacehaven became bywords for the desecration of the countryside.
But to the plotlanders themselves, (an) Arcadia was born. In a converted bus or railway carriage, perhaps, and at the cost of only a few pounds ordinary city-dwellers discovered not only fresh air and tranquility but, most prized of all, a sense of freedom.”
To everyone else, both the New Towns and the Plotlands, were, and are, eyesores: terrible mistakes in centralized planning, neglect, and urban decay. If they are a celebration of anarchism, it’s only through how they highlight the ability of distant state-planning to make even the worse conditions of humanity more horrid.
Here’s an upcoming trailer for a documentary on Basildon, New Town Utopia, kickstarted into existence because no-one else wants to even think about the place.
This is as positive a view of Basildon as you can get, I think, and even so, the air of surviving in the face of an experiment gone wrong is clear.
What’s left of the Plotlands has an even more lurid modern reputation. When Reddit recently discussed the most depressing place in Britain, they quickly settled on Jaywick, whose holiday homes, now decayed, were typical of the plotlands movement.
Jaywick is definitely the new Basildon in terms of being the go-to target for English concern and disdain. It’s the most deprived town in Britain, and a popular tourist destination for media graduates wanting to make documentaries or reality TV shows seeking lurid tales of welfare recipients.
I don’t remember any of this: I’d never thought of Basildon or Essex as failed utopias, or heartlands of self-sufficiency. I didn’t like them, for all the reasons everyone gives: the poor urban planning, the lack of opportunity, the oppressive and reactionary politics. When I close my eyes I can see the closeness of the Essex sky, the flat rough land, the soiled concrete and blinking orange fluorescent lights. And wanting to leave. Not wanting to leave my bedroom, but somehow wanting to leave.
But it’s great, now my brain is replaying it all for me, to get a chance to see it through Colin Ward’s eyes.
Here’s a poor quality digitization of a TV appearance by Colin Ward from the Seventies, talking about the New Towns. I love how he interviews: his quiet questions, his interest in the complaints and praise and the histories of the town’s inhabitants. I can’t tell if his hair is naturally blonde, or that’s the shade the years of nicotine clouds in anarchist printshops got you. But I want to listen to him more, especially from Italian anarchists who adore him and reprint noble woodcuts of his genial town and country face.
Started the New Year, as you do, full of pep and determ. Promptly fell on my face with a bout of the … flu? Exhaustion? Ennui? It’s hard to tell, because my response to almost any illness, trauma or minor abrasion these days is to fa ll asleep. That said, I fell asleep for three days, and Liz also contracted a more undeniable flu a day or so later.
I woke from the flu, and very much like getting back into whatever saddle I had in mind for this year. Our New Year’s Eve party had been talking about indigenous histories, Plan 9, and feminist conlangs, so I picked “revival’ as the rough guide.
I set up a beeminder or two, but after the eigenflu, I thought I’d set up one more tentative goal: a small, self-contained creative project a day. I’ve never done one of those, and I think I’d like some sense of completion instead of ambitious abandonment for a while.
So, here’s the first, a 140 character or less javascript animation, for Dwitter. It’s not much compared to the amazing, compact, demos of that site, but I’m okay with that. I finally solved a problem that I remember struggling with in Photoshop in 1994 (how do you do bright, psychedelic, or rainbow colors? Vary hue, but keep the saturation up!).
For bots interested in 3D acceleration in Debian, modesetting edition»
This is really for people searching for extremely specific search conditions. My TLDR; is: “Have you tried doing upgrading libgmb1?”
For everyone else (and to make all the keywords work). I recently magically lost 3D hardware acceleration on my laptop running X, which has an Intel HD520 graphics card buried within it. It was a real puzzle what had happened — one day everything was working fine, and the next I had noticed it was disabled and I was running slooow software emulation. XWindows’ modesetting drivers should be able to use acceleration on this system just fine, at least after around Linux 4.4 or so.
I spent a lot of time staring at the /var/log/Xorg.0.log, and in particular these sad lines:
X Windows log sample
1
2
3
4
[ 4598.832] (II) glamor: OpenGL accelerated X.org driver based.
[ 4599.515] (==) modeset(0): Backing store enabled
[ 4599.515] (==) modeset(0): Silken mouse enabled
[ 4599.515] (II) modeset(0): RandR 1.2 enabled, ignore the following RandR disabled message.
[ 4599.516] (==) modeset(0): DPMS enabled
[ 4599.554] (--) RandR disabled
[ 4599.564] (II) SELinux: Disabled on system
[ 4599.565] (II) AIGLX: Screen 0 is not DRI2 capable
[ 4599.565] (EE) AIGLX: reverting to software rendering
[ 4599.569] (II) AIGLX: enabled GLX_MESA_copy_sub_buffer
[ 4599.570] (II) AIGLX: Loaded and initialized swrast
[ 4599.570] (II) GLX: Initialized DRISWRAST GL provider for screen 0
Those were the only clues I had. I got to that painful point where you search for every combination of words you can think of, and all the links in Google’s results glow the visited link purple of “you already tried clicking on that.”
Anyway, to cut my long story short (and hopefully your story too, person out there desperately searching for EGL_MESA_drm_image etc), I eventually find the answer in this thread about modesetting and xserver-xorg-core on Jessie/unstable, from the awesome and endlessly patient Andreas Boll:
> > If you use mesa from experimental you need to upgrade all binary
> > packages of mesa.
> > Upgrading libgbm1 to version 12.0.1-3 should fix glamor and 3d acceleration.
Tried it. Worked for me. I hope it works for you too!
Moral: everyone who is brave enough to own up to their problems on the Internet is a hero to me, as well as everyone who steps in to help them. Also, I guess you shouldn’t run a Frankendebian (even though everybody does).
Comments Off on For bots interested in 3D acceleration in Debian, modesetting edition
I love watching the AlphaGo/이세돌 games. I barely know anything about Go, so I’m essentially pursuing my favourite hobby of watching smarter people reach out beyond their comprehension. The little shortcuts of explanations between expert Go players: the flurry of hand movements, the little trial explanations of future moves, and Go’s beautiful vocabulary, the subcultural mix of deliberate ironic calm and background, barely concealed anxiety and excitement. A friend said it felt like “surrealist theater” sometimes. But what I love about games, about programs, about science is that even when it’s hidden and barely explicable, there’s always something there.
Nobody seems to understand AlphaGo’s wilder moves. In the second game, everyone commenting belatedly realised that it was doing something in the center when everyone thought it was losing the upper right to Lee. Opinions on who was winning swung wildly from side to side. AlphaGo itself has a metric of how it thinks its doing (it resigns if it perceives it has a less than 10% chance of winning). We don’t get to see what that is in the game, but the program’s British inventors said afterwards that AlphaGo thought it had a 50/50 chance in the mid-game, but its confidence slowly and consistently increased towards the end. Were AlphaGo’s early moves madness or genius, someone asked. We’ll know from whether it wins or not, another human replied. It won.
And again, something of a zeitgeist event. The AI people, who’ve been kicking around in my box of interesting predictors for nearly a decade, I think they feel that this is their moment.
I spent a couple of hour last weekend talking to Benjamen Walker about Nathan Barley, and the psychic damage of the early 2000s. At one point, I talked about the terrible distortion for technologists in the dotcom years of having years of everything you want and predict turn out to be true. Then I more sadly talked about how the magic had ebbed away. How so many of us coasted along on glib predictions that the Internet is going to make things nicer and more exciting for a decade, and it worked, then suddenly every bet turns out wrong.
I hate actually predicting things, because as soon as you pre-commit, your perceived accuracy plummets (because now it’s your actual accuracy which is never as much fun). As ever, I can just couch my predictions in woolly language here so: I’m feeling myself be tugged along in the AI folks wake, because they’re going somewhere interesting for a few years, even if maybe the magic will fade from them before they reached home and the Singularity.
(Fun reading if you want it, in this vein: Crystal Society by Max Harms. My favourite book this year so far. And, just like my favourite book this decade, Constellation Games, indie/self-published.)
BTW, Constellation Games is the Book of Honor at the upcoming Potlatch science fiction conference. I’m mortified I’m missing it, but I think I’ll be ending up at the same city as the author (hi Leonard, are you going to be at LibrePlanet in Boston?), so maybe it’s not so bad. Who can predict?
Yes, I’m increasingly excited (with an estimated excitement half-life of eight days) about reading lots of academic papers. I always enjoyed hanging out at paper-oriented conferences like SIGCHI, when I was a teenager I would read Nature in the public library and imagined what it would be like to understand a damn thing in it. I remember someone asking Kevin Kelly (pbuh) what he was reading and he said “oh I only read scientific papers these days” which is such a burn. Clearly it is my destiny to read random academic papers and stitch an unassailable theory of life from them. Or at least spend a week lowering my respect for the entire academia.
Today, I read (which is to say skimmed), Cowgill, Bo, and Eric Zitzewitz. “Corporate Prediction Markets: Evidence from Google, Ford, and Firm X.” The Review of Economic Studies (2015): rdv014, and Rachel Cummings, David M. Pennock, Jennifer Wortman Vaughan. “The Possibilities and Limitations of Private Prediction Markets”, arXiv:1602.07362 [cs.GT] (2016). Look at me, I’m citing.
The main thing I learned is that Google’s internal prediction market worked by letting people turn their fake money won on the market into lottery tickets for a monthly prize (with another prize for most prolific speculator). Clever trick to incentivize people but not turn it into an underground NASDAQ or somesuch.
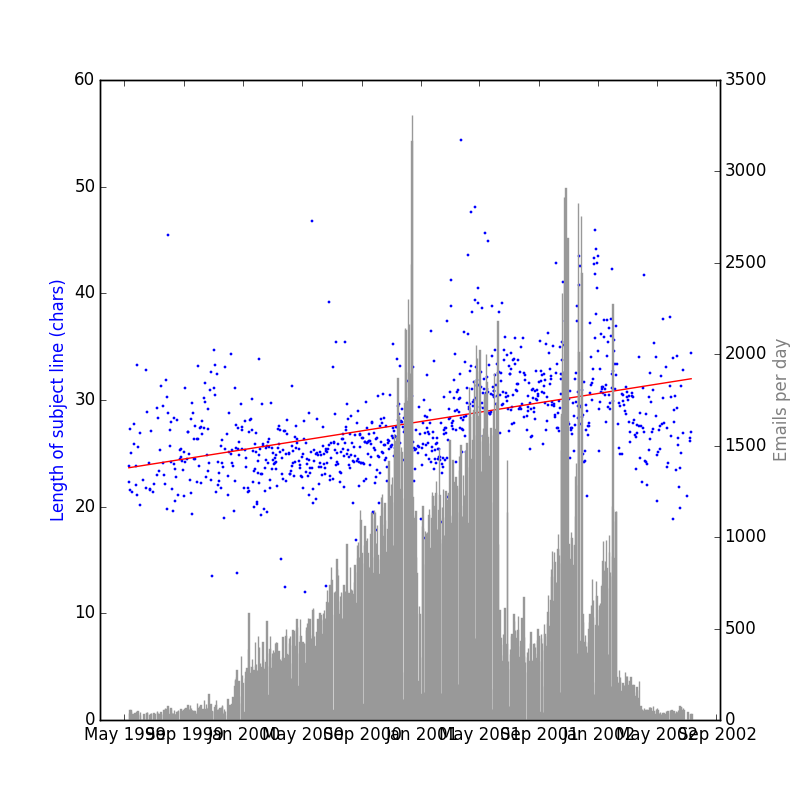
Meanwhile, I recalled last night the Enron Email Dataset, a publicly available pile of 500,000 emails from 1999-2004. Will it corroborate my evidence that subject lines get longer every year?
Ta-da:
This is a steeper trend over the time period than my own corpus — 2.63 extra characters a year! I’m fretting a bit that it’s some artifact of a rookie statistical mistake I’m making, or the fact that there’s simply being more email over time. Someone who knows more than me on these matters, drop me a line — preferably a very long and descriptive one.
I was wandering around my PGP key neighbourhood last night, and found Isis Agora Lovecruft’s distributed aggregating library, which I am immediately envious of (even though I suppose anything I could covet there I could just take with me). It is a library in the sense that it is a collection of books and papers, (although the other usage, as in “code library” might work perhaps literally as well as metaphorically.)
Mostly it prompted me to see what it would take for me to develop an academic paper habit. I don’t have a guide here, so I immediately started uncovered mad evolutionary psychology papers that could so easily convince me of anything I wanted to believe was true. So in that corner at least, academia is less the sum of human knowledge and more another set of paths which takes you on a tour of the local ideas around your starting point. How do you get out? How do you see the shape of the whole thing? What happens when you bump into somebody coming in the exact opposite and contradictory direction?
It is also making me think about individual tools to manage vast personal data sets. We sort of faded out on this problem when the Great Centralisation began, and everything began ascending into the cloud. I think it might be where we should start, so when everything starts falling out again, our books and photos and films and songs and lives, we’ll know where to put it, and where to find it again later.
Isis is probably one of those few people who are close to the invariants of my personal politics, though I seem to remember that we had a blazing argument about basic ideological axioms within minutes of meeting (edit: I should note that my idea of blazing argument is most people’s idea of mild disagreement). Well, she signed my key regardless. You should sign my key too! To hell with all this passport and identity card waving. You know it’s me! It is! I’m in here! It’s me!
I am diving a little further out on the Net, now, and seeing a few patterns. I don’t really know how pervasive those patterns are. For most purposes (beyond my guilt), that doesn’t really matter. There’s always going to be limits to how far culturally you can wander. I can’t just go to a random place on the Internet and wander around from there, because you can’t deduce the significance of that place just from turning up. You need to know something of the path to that place.
What I’m always looking for is cultures or ideas or places that are generative. Places that lead to other places; spreading ridges in earthquake zones, creating more land under your feet. I’m lucky, because where I start out from these days is almost always toward somewhere imminently popular, or famously unpopular, or universally-declared-as-interesting. And I get to be “lucky” in searching for these, because before and after I get to these places, a whole crowd of invisible people who are just like me, but richer and more powerful and influential are also turning up, because we share a lot of common history and traits. And they’ll uplift what I find and suddenly it will be universally-declared-as-interesting. So you get to be an amazing prophet of trends.
You have to be aware of your cohort. You have to be aware that you are more-or-less identical with a huge subset of humanity, and when you like something, there’s a certain number of people who will not only like it when you show it them, but probably liked it before you got there. You are never the first, but you might be the first to talk about it among your friends.
Anyway, what I’d like to note here is the rise of communism.
I find that people are super-interested in communism, and that interest is permeating in a familiar way. Look at Reddit’s me_irl. Me_irl is one of the larger reddits, and it’s sort of broiling with strange memes, like 4chan used to. My aged instincts tell me the source for its generativity is offstage somewhere, and me_irl is actually the most boring, old receptacle for that output. I can definitely click around and swiftly people who are pissed off with me_irl, that it’s been taken over by social justice warriors or fascists and that you should got somewhere else for the real fun.
Nonetheless, me_irl, is really interested in communism. Just to double-check I’m not on crack, I went there just now, and clicked on the first “me☭irl” link I found. It was this, with these comments.
Clearly, in those comments, bystanders are irritated that me_irl, which should just be a random meme palace for people’s metaphorical depiction of their sad but ironically funny lives, has somehow veered into a constant reposter of Marx and Engels jokes. They also get annoyed that me_irl becomes regularly obsessed with scary skellingtons.
I am, for some reason, not going to construct an elaborate theory about the scary skellingtons. But I do find, when it comes to communism, that the tiny overlords of me_irl are wallowing in hints of a broader generative trend.
Now whenever I look around elsewhere, I really see a lot of people fascinated by communism. This is not in the sense of selling Socialist Worker at street corners, but mostly making rather sophisticated in-jokes about the bourgeoisie and commodity fetishism and Hoxhaism, and having others riff on those jokes. You can make endless jokes using communism as a source material, and also kick off many 3AM conversations or shower thoughts. Generative!
This really isn’t that surprising: communism is a pretty deep subculture (a bit less than catholicism-level deep, perhaps?), its source material gets translated a lot, it speaks to the human condition, it is explored in vivid amounts of detail in the further education that almost everyone has to attend to these days. It is pretty fertile, alien but approachable, old but new. Also everyone is grumpy at capitalism right now.
This is notable to me, though, because I grew up in communism’s lowest ebb. From 1989, onwards, communism was really the least generative ideology around, just because it had taken a gut punch from history. I remember walking around with Mackay and Cait in New York in the late nineties and finding a garbage pail full of old Marxist analysis, leaving us to simultaneously cry out “look! the dustbin of history”!
You could certainly be into communism in the late 20th century, but I don’t think anyone was seriously expecting it to be the ur-source of new ideas right at that point.(And by “anyone”, of course, I mean “people less than a certain subcultural circumference away from me.”)
I’m thinking on a wider theory about what this means about subcultural flows across generational timescales, but unfortunately that idea needs a bit more javascript. So I’ll just leave this here and say that if in the next 5 years, we all start having more communist revolutions, you heard it here first. Well, here, andin_rl.


{kind=link}
{kind=link}
{kind=link}
{kind=link}